【tabby 案例随笔】XML-RPC RCE CVE-2023-49070
#1 前言
这几天,ofbiz 出了一个认证绕过导致的 xml-rpc 反序列化漏洞。在复现过程中,发现用 tabby 跑实际的漏洞链路会非常长,导致无法在个人电脑上完成利用链的检索。
本文将讨论 tabby 的另一种规则扩展方法,使得在个人机器上遇到函数调用链路过深的情况也可以查询出对应的漏洞链路。
#2 环境搭建
影响版本:Apache OFBiz < 18.12.10 受影响版本下载地址:https://archive.apache.org/dist/ofbiz/apache-ofbiz-18.12.09.zip 修复版本下载地址:https://archive.apache.org/dist/ofbiz/apache-ofbiz-18.12.10.zip
解压后,直接用 dockerfile 起不来,如果可以起来忽略下面的操作 执行命令 ./gradlew build 修改 dockerfile,注释掉 FROM eclipse-temurin:8 AS runtimebase 前的语句,修改解压缩 ofbiz.tar 的操作为下面的内容。
# Extract the OFBiz tar distribution created by the builder stage.
COPY ./build/distributions/ofbiz.tar /tmp/ofbiz.tar
RUN ["tar", "--extract", "--strip-components=1", "--file=/tmp/ofbiz.tar"]
#3 漏洞分析
ofbiz 之前在 20 年的时候出过 xml-rpc 的 rce 漏洞(CVE-2020-9496),当时是 pre-auth 的,后续官方给 xmlrpc 接口加了鉴权操作,修复见 链接 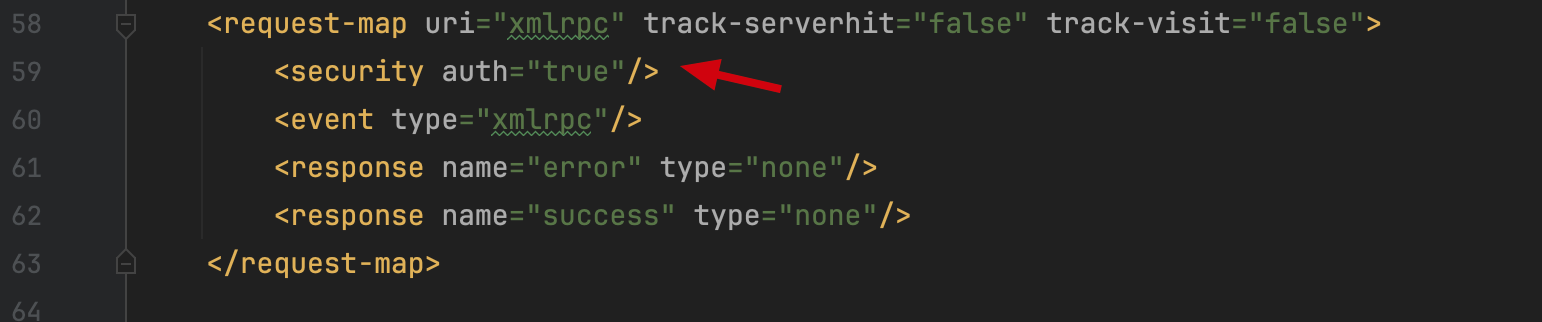 而本次 CVE-2023-49070 提示的还是 pre-auth,那么意味着这次漏洞存在权限绕过的问题
而本次 CVE-2023-49070 提示的还是 pre-auth,那么意味着这次漏洞存在权限绕过的问题 org.apache.ofbiz.webapp.control.RequestHandler#doRequest 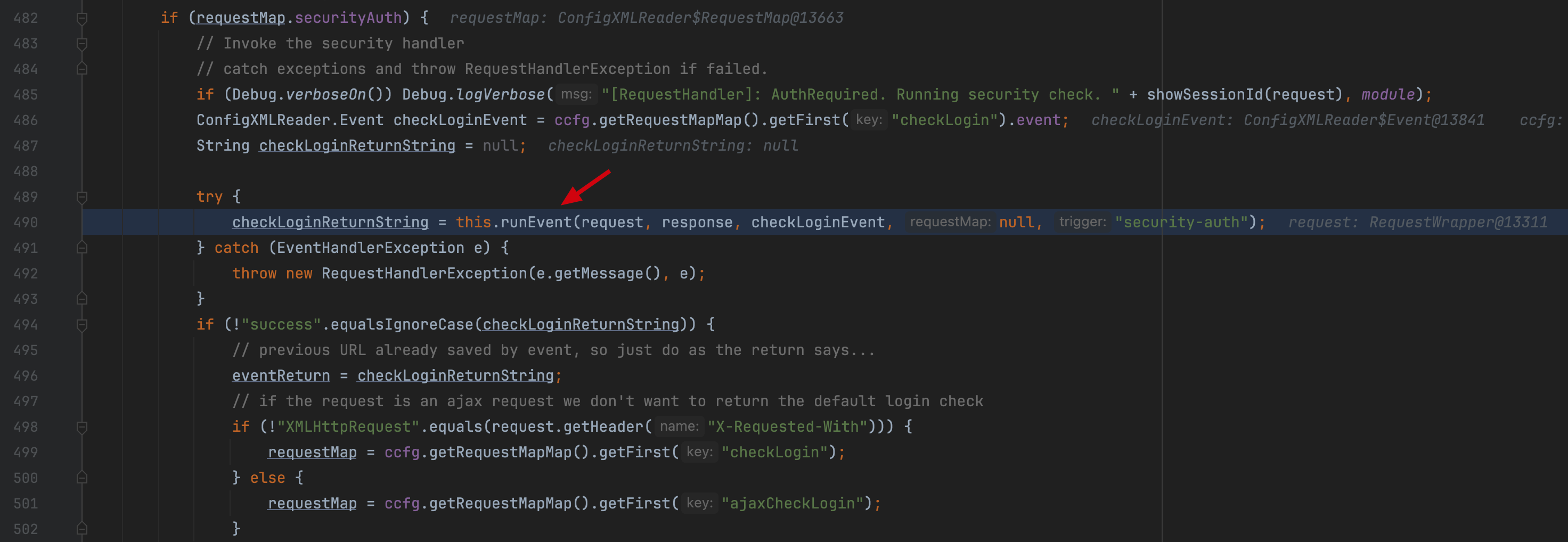 在 doRequest 函数中,处理当前 url 的 event 之前,会根据当前 requestMap 是否设置 security auth 为 true 来决定是否需要进行登陆确定。调用到 checkLogin 所对应的 event 后,返回的
在 doRequest 函数中,处理当前 url 的 event 之前,会根据当前 requestMap 是否设置 security auth 为 true 来决定是否需要进行登陆确定。调用到 checkLogin 所对应的 event 后,返回的 checkLoginReturnString 如果为 success 时,此处的 eventReturn 将仍保持为 null。在后续执行对应的 event 前,会有如下判断  仅当 eventReturn 为 null 才能进入后续的 event 调用流程。 而正常未登陆的情况下,checkLogin 返回的为 error,后续的
仅当 eventReturn 为 null 才能进入后续的 event 调用流程。 而正常未登陆的情况下,checkLogin 返回的为 error,后续的 eventReturn 会被赋值为 error,因此进入不了后续的 event 执行流程。 那么,很明显 checkLogin 所对应的函数执行存在鉴权上的问题。 org.apache.ofbiz.webapp.control.LoginWorker#extensionCheckLogin 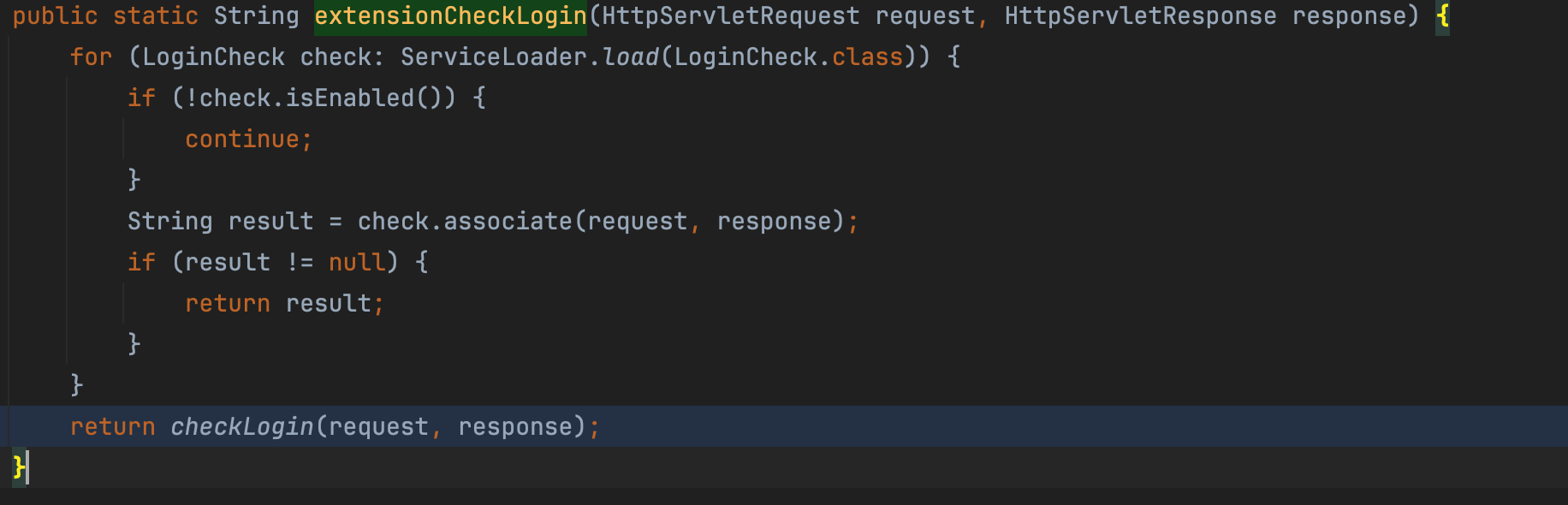
org.apache.ofbiz.webapp.control.LoginWorker#checkLogin 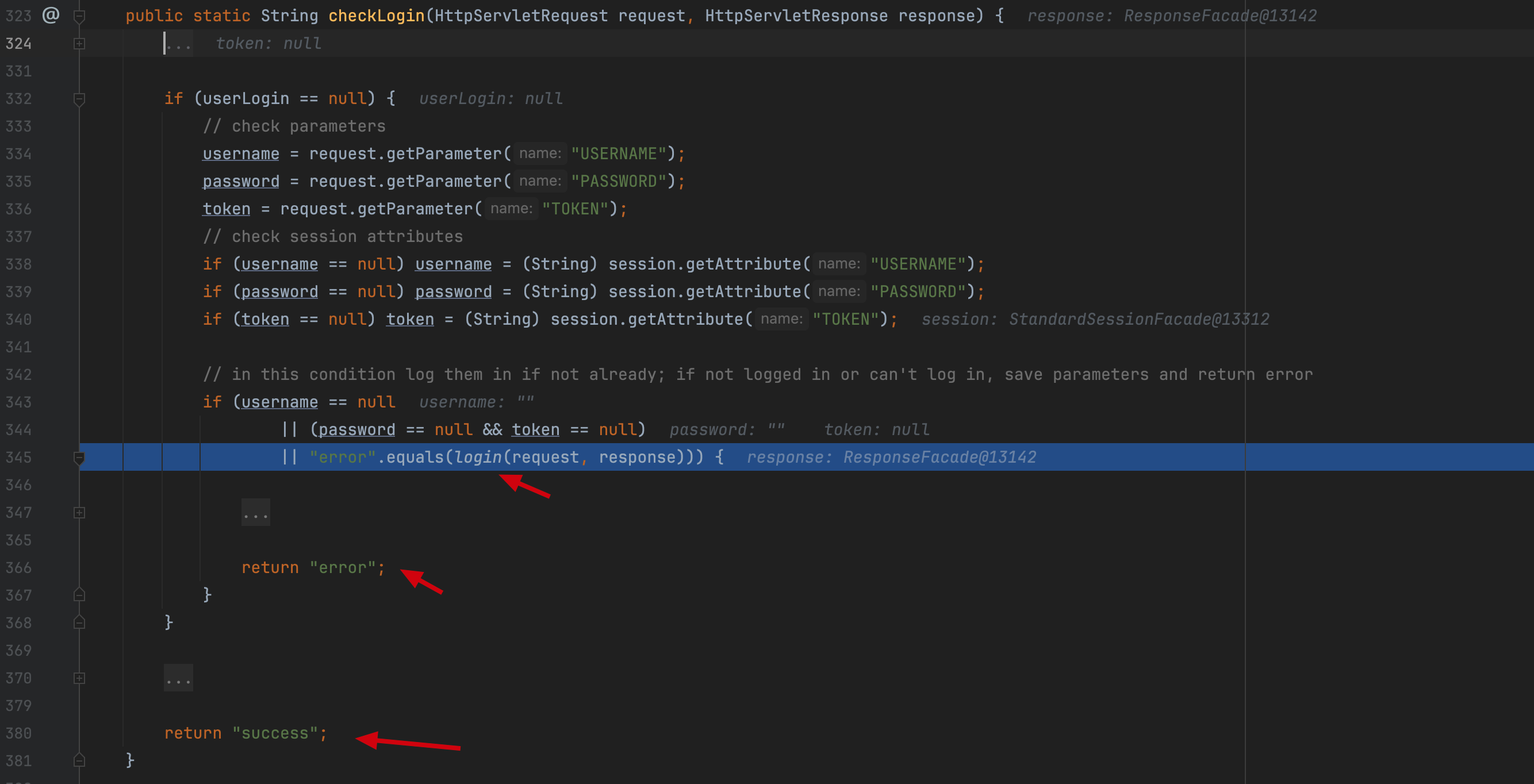
org.apache.ofbiz.webapp.control.LoginWorker#login 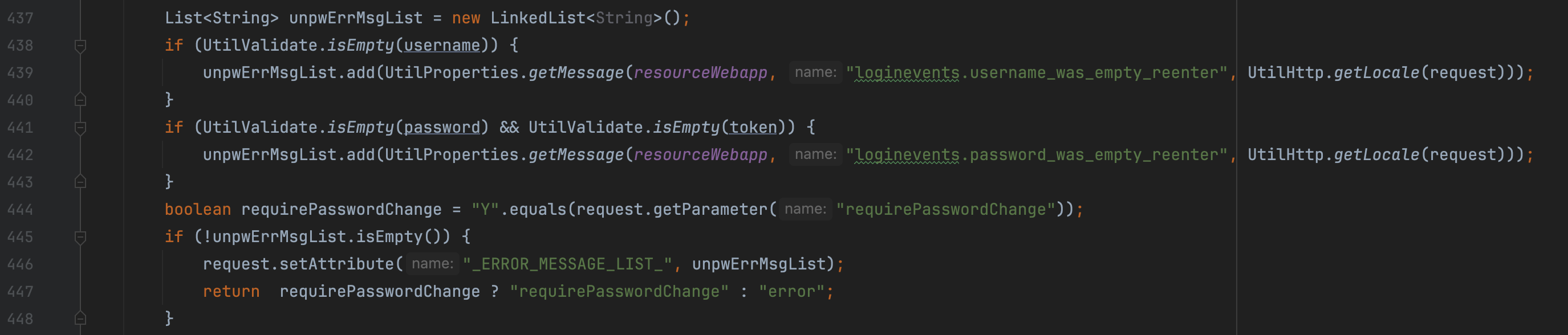 函数 login 里面有这样一个逻辑,当参数中包含
函数 login 里面有这样一个逻辑,当参数中包含 requirePasswordChange 且为 Y 时(unpwWErrMsgList 可以控制 username 和 password 为空来插入值),返回的字符串为 requirePasswordChange 而非 error 那么在 checkLogin 函数处进入不来 345 处的 if 分支,也就最终返回不了 error 字符串,而返回 success,最终绕过 securit auth 的认证。
那么,接下来的内容跟之前 CVE-2020-9496 是一样的,构造好 xml-rpc 的反序列化 payload 触发反序列化即可。
另外,这里需要注意下org.apache.ofbiz.base.util.CacheFilter#doFilter 检查了xml-rpc 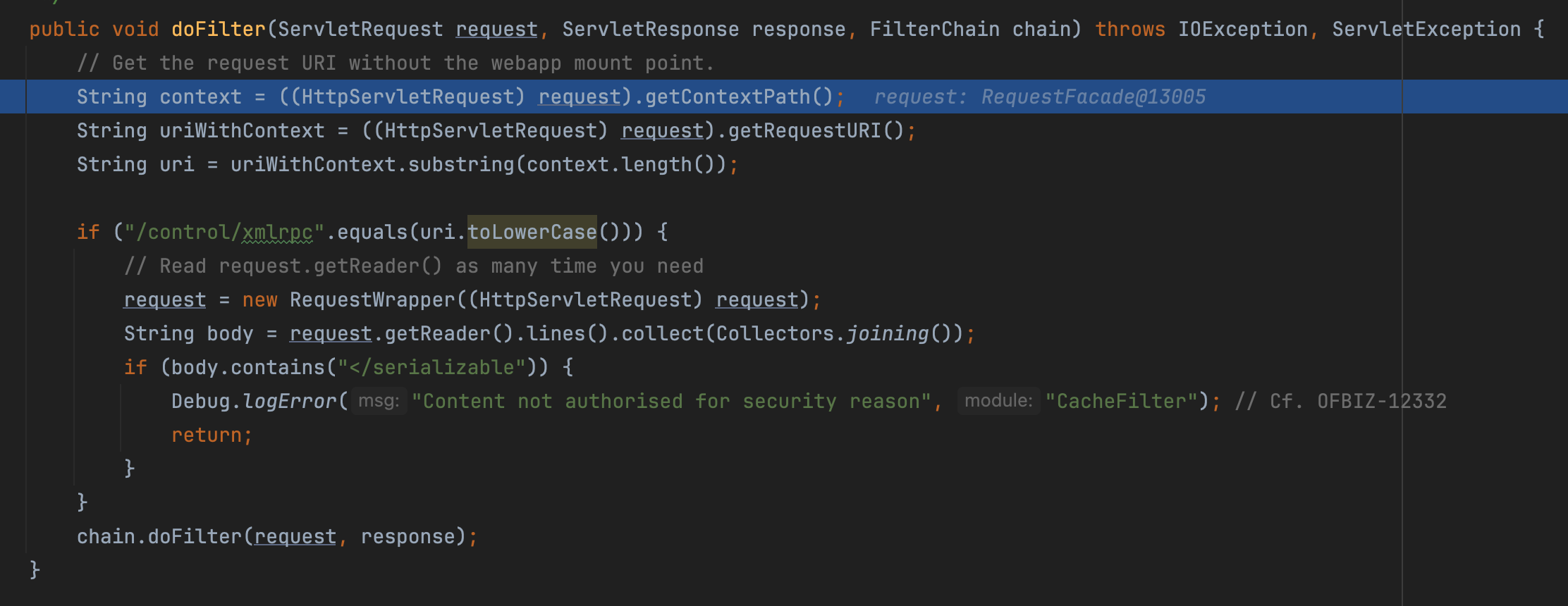 绕过方法比较简单
绕过方法比较简单</serializable 改成 < /serializable 或者 url 改成 /webtools/control/xmlrpc;?xxx 或者 /webtools/control/xmlrpc//
#4 漏洞修复
官方将 xmlrpc 接口和 xml-rpc 相关依赖都删除了,修复的很暴力 https://github.com/apache/ofbiz-framework/commit/c59336f604f503df5b2f7c424fd5e392d5923a27#diff-15bd438825c15daa959003c7ff3a5d7dc30c34e86e1cb5f7102be19464ebccb8 但是,很奇怪的是这里的认证绕过貌似并没有修复 https://github.com/apache/ofbiz-framework/blob/c59336f604f503df5b2f7c424fd5e392d5923a27/framework/webapp/src/main/java/org/apache/ofbiz/webapp/control/LoginWorker.java#L444  那么是不是在 webtools 或其他域下注册的 event 都是可以绕过的?或许其他 event 所对应的函数调用在没有做鉴权的情况下,仍然产生安全问题。
那么是不是在 webtools 或其他域下注册的 event 都是可以绕过的?或许其他 event 所对应的函数调用在没有做鉴权的情况下,仍然产生安全问题。
#5 回到tabby规则优化上
这个漏洞主要有两个部分:鉴权绕过和 xml-rpc 反序列化。 由于 tabby 并没有处理字符串比较的分析,还没办法做此类问题的检测,不过这个确实可以作为一个后续的方向。 第二部分 xml-rpc 反序列化,原理这篇文章将的很清楚了,不过多赘述。 在实际查找整一条链路的时候,会发现深度过深,查找时间会很长。这里尝试分开来查找对应的路径。 首先是xml-rpc这边的链路,节点数8
match (source:Method {NAME0:"org.apache.xmlrpc.parser.XmlRpcRequestParser#endElement"})
match (sink:Method {IS_SINK:true, NAME:"readObject", HAS_PARAMETERS:false})
call tabby.algo.findPath(source, "-", sink, 10, true) yield path where none(n in nodes(path) where n.NAME0 in ["java.util.Iterator#hasNext","java.lang.Runnable#run","java.util.Enumeration#nextElement"])
return path skip 2 limit 1
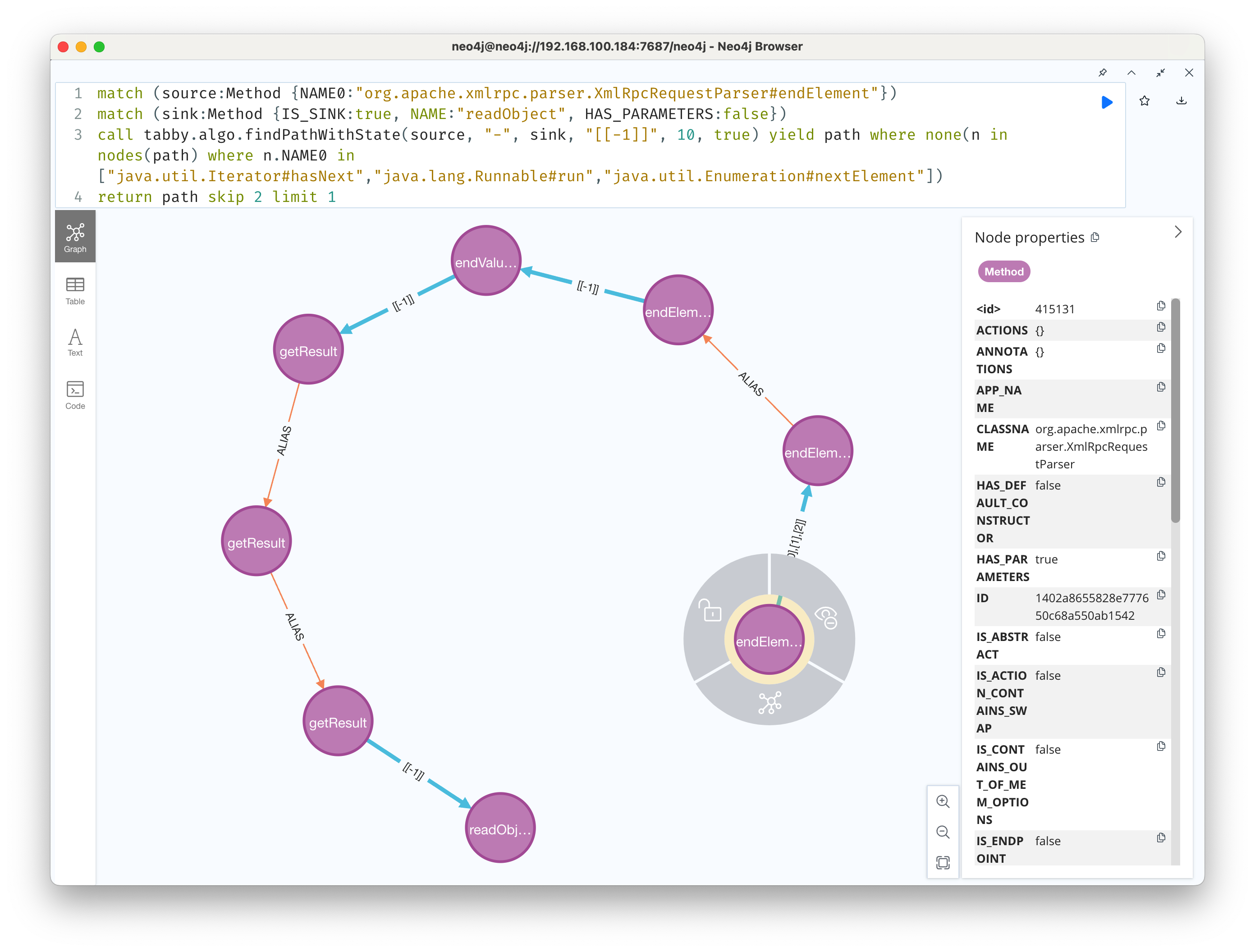 这里没有问题,再尝试找一下ofbiz上的链路,这里根据前面的分析,我们直接以
这里没有问题,再尝试找一下ofbiz上的链路,这里根据前面的分析,我们直接以org.apache.ofbiz.webapp.event.XmlRpcEventHandler作为source,sink是上一条的开始 match (source:Method {NAME0:"org.apache.ofbiz.webapp.event.XmlRpcEventHandler#invoke"})
match (sink:Method {NAME0:"org.apache.xerces.parsers.AbstractSAXParser#endElement"})
call tabby.algo.findPathWithState(source, "-", sink, "[[-1]]", 18, true) yield path where none(n in nodes(path) where n.NAME0 in ["java.util.Iterator#hasNext","java.util.Iterator#next","java.lang.Runnable#run","java.util.Enumeration#nextElement","java.io.Writer#write","org.apache.xmlrpc.server.XmlRpcStreamServer#writeError","org.apache.xmlrpc.server.XmlRpcStreamServer#writeResponse","nu.xom.xslt.XOMReader#parse","com.sun.xml.fastinfoset.sax.SAXDocumentParser#parse","org.ccil.cowan.tagsoup.Parser#parse","org.apache.xerces.parsers.NonValidatingConfiguration#parse","org.apache.xerces.impl.xs.opti.SchemaParsingConfig#parse","java.io.Closeable#close","org.cyberneko.html.HTMLScanner#scanDocument"])
return path limit 1
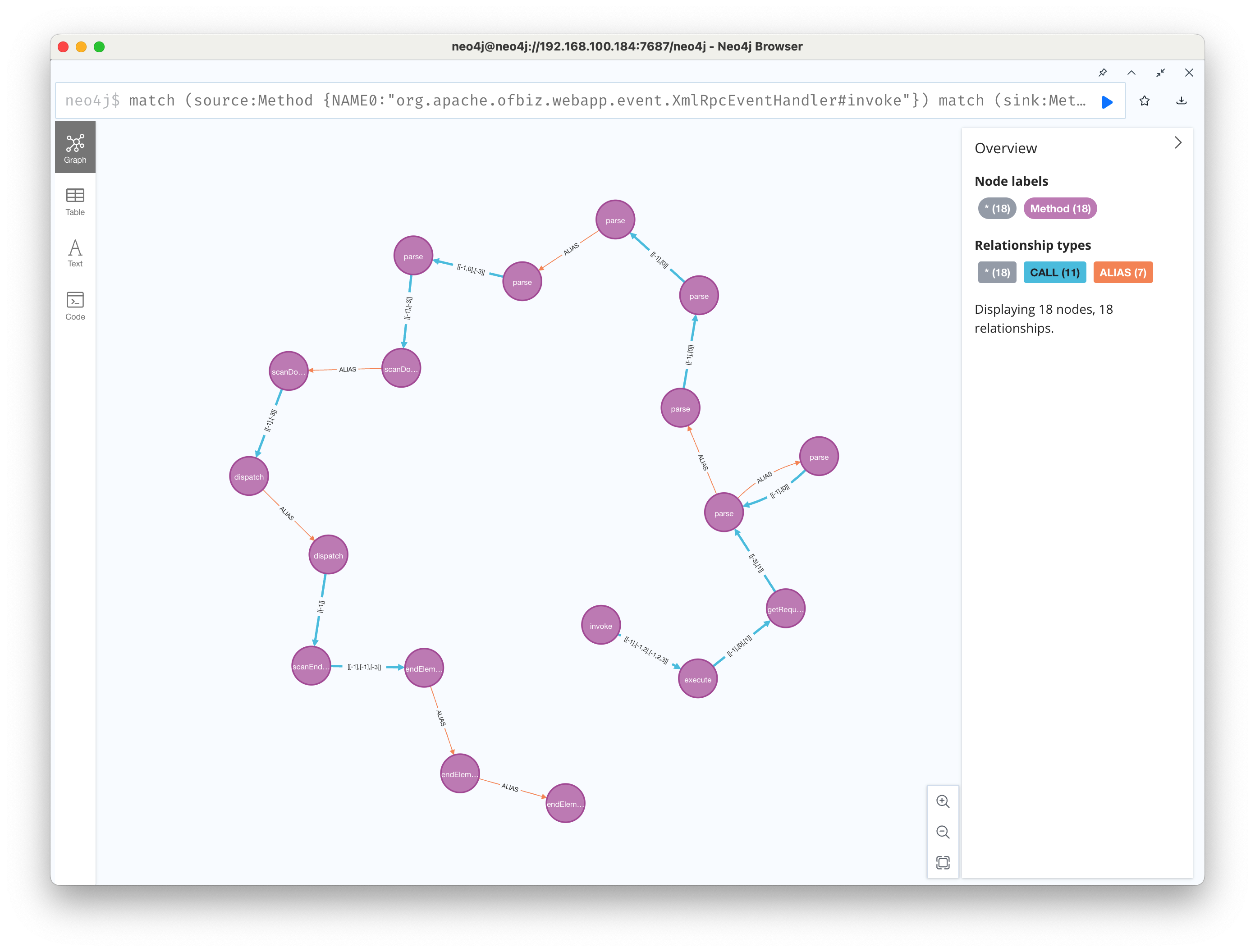 人工计算一下污点情况,两条合并后的污点是符合传递规则的。但是两条合并后一共25个节点,查询深度需要提到26才可以,这个深度查询速度有点感人,等了很久都没有出来。 这种情况也是 tabby 这套方案的一个瓶颈。虽然图上完整建立了调用链路,但是由于neo4j性能限制,对于过深的深度路径查询需要花费很长时间。
人工计算一下污点情况,两条合并后的污点是符合传递规则的。但是两条合并后一共25个节点,查询深度需要提到26才可以,这个深度查询速度有点感人,等了很久都没有出来。 这种情况也是 tabby 这套方案的一个瓶颈。虽然图上完整建立了调用链路,但是由于neo4j性能限制,对于过深的深度路径查询需要花费很长时间。 那么问题来了,实际情况下,我们确实会遇到类似的问题,怎么去补救这种情况呢? 其实tabby预留了人工建边的能力 https://github.com/wh1t3p1g/tabby/tree/master/src/main/java/tabby/core/model model下面的类将处理图建边的过程,这里我们可以尝试给 xml-rpc 做一个特例。 这里我们将 xml-rpc 这个漏洞的触发作为先验知识 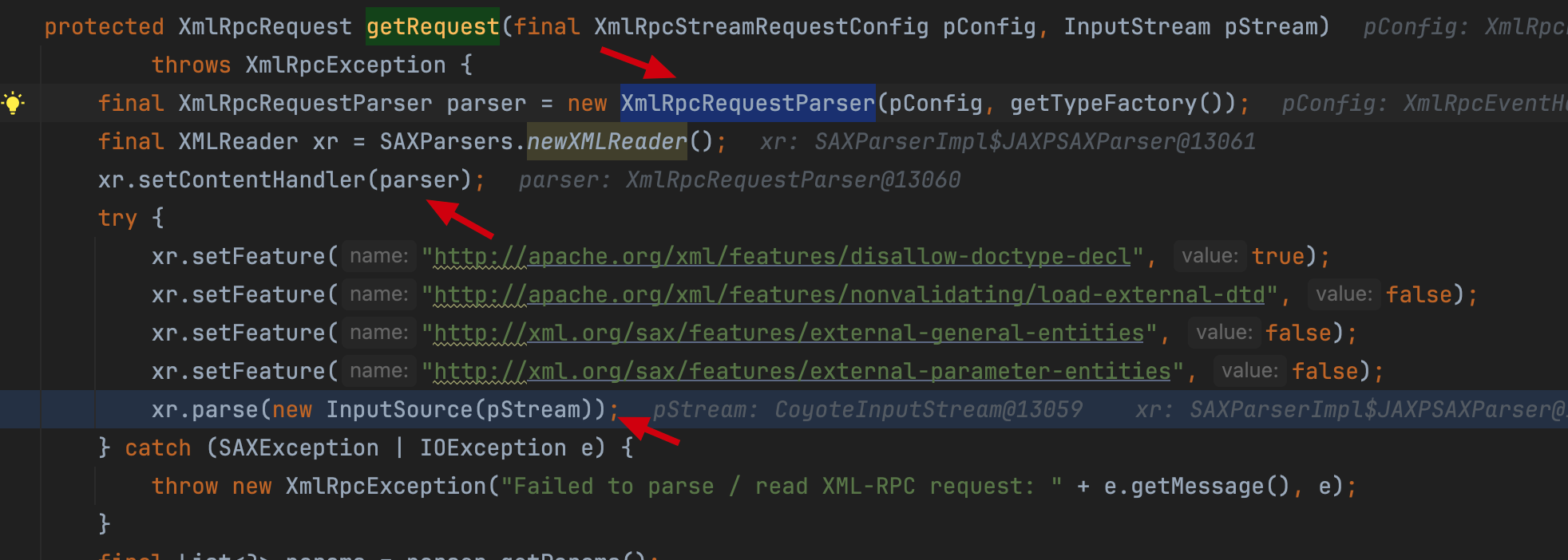 这个漏洞的触发需要3步: 1. 初始化 XmlRpcRequestParser 2. 设置为xmlreader的ContentHandler 3. 最后,parse的input source是可控的 那么,我们可以对这个xml-rpc的漏洞进行建模。 本着宁可错杀不可遗漏的原则(一般input source很难去推断是否可控,类似存在读入xml文件但文件可控的情况,在静态分析上很难做判断是否可控),我们取前两个为sink调用点的识别 也就是当XMLReader.setContentHandler设置的是XmlRpcRequestParser类型时,可能存在xml-rpc这个漏洞。
这个漏洞的触发需要3步: 1. 初始化 XmlRpcRequestParser 2. 设置为xmlreader的ContentHandler 3. 最后,parse的input source是可控的 那么,我们可以对这个xml-rpc的漏洞进行建模。 本着宁可错杀不可遗漏的原则(一般input source很难去推断是否可控,类似存在读入xml文件但文件可控的情况,在静态分析上很难做判断是否可控),我们取前两个为sink调用点的识别 也就是当XMLReader.setContentHandler设置的是XmlRpcRequestParser类型时,可能存在xml-rpc这个漏洞。 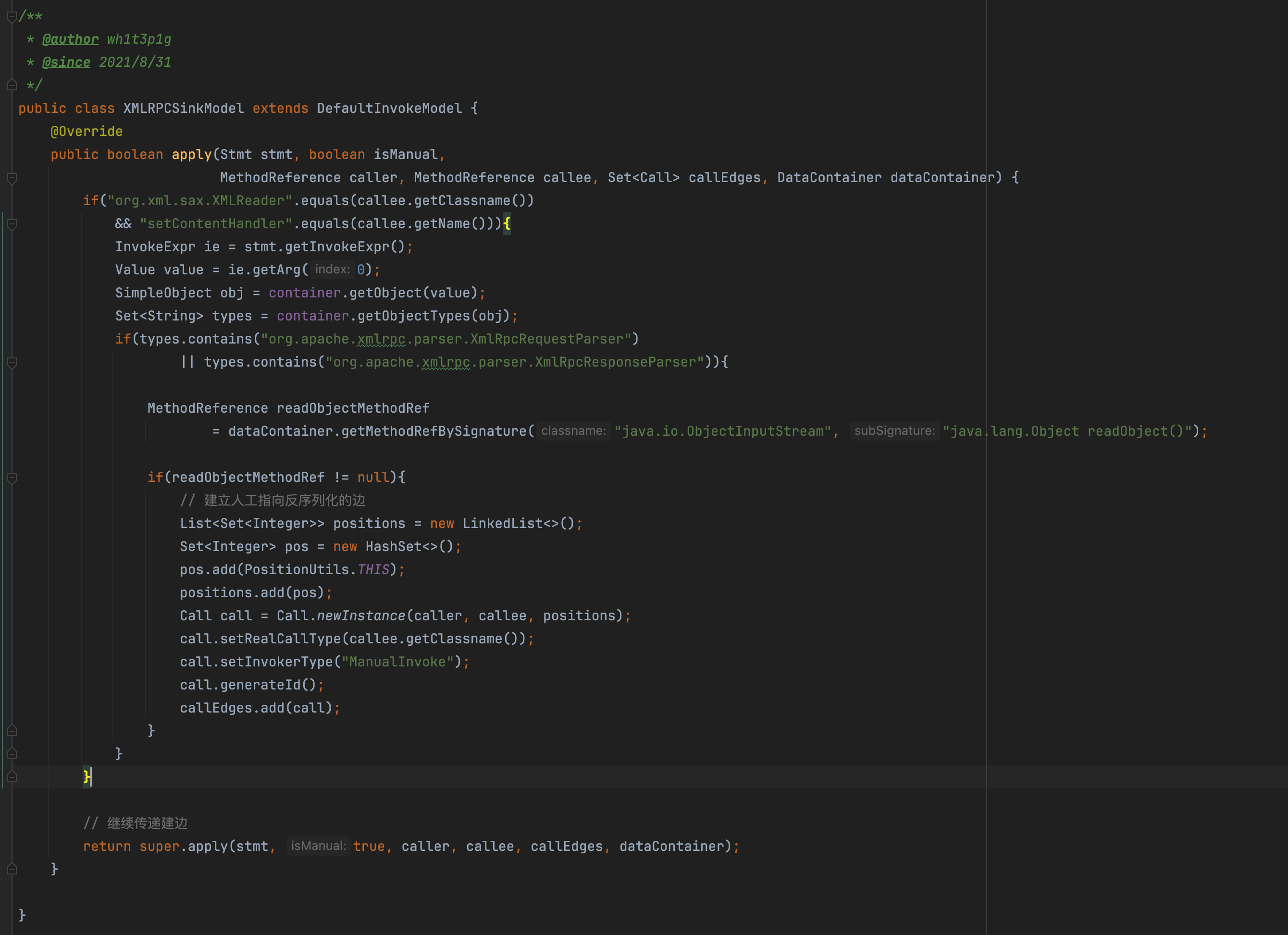 这里的逻辑是当XMLReader.setContentHandler的参数类型是下面两种类型之一时,建立一个指向反序列化readObject函数的人工边 1. org.apache.xmlrpc.parser.XmlRpcRequestParser 2. org.apache.xmlrpc.parser.XmlRpcResponseParser 通过这个方式,我们重新跑一下查询后得到一条深度为4的调用路径。
这里的逻辑是当XMLReader.setContentHandler的参数类型是下面两种类型之一时,建立一个指向反序列化readObject函数的人工边 1. org.apache.xmlrpc.parser.XmlRpcRequestParser 2. org.apache.xmlrpc.parser.XmlRpcResponseParser 通过这个方式,我们重新跑一下查询后得到一条深度为4的调用路径。 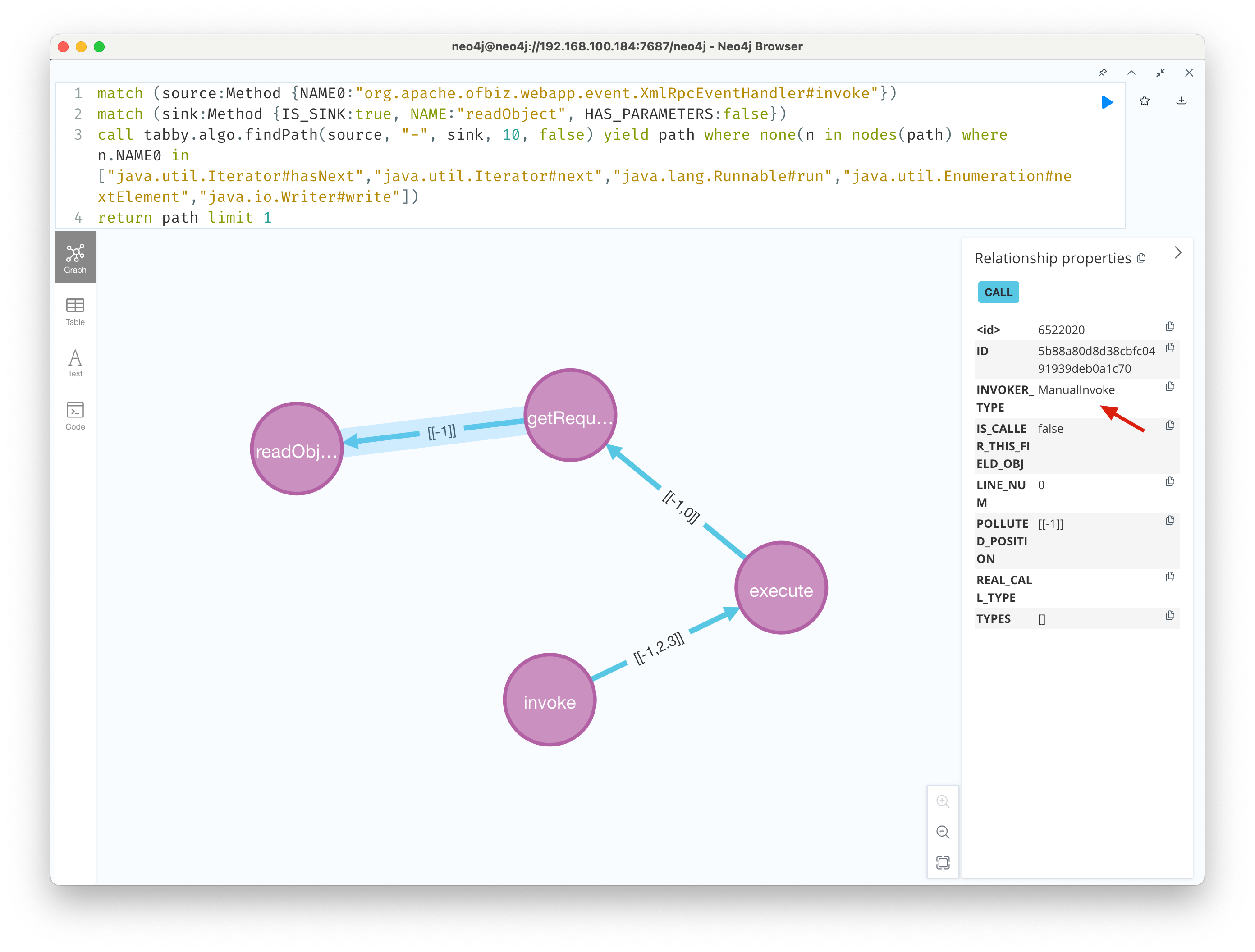 这种深度10以下的链路对于个人机器还是很友好的 XD
这种深度10以下的链路对于个人机器还是很友好的 XD